This is a proposal and presentation prepared for the Site Platform commission. Please scroll down for the presentation and slides.
Proposal
Brief summary of your proposal
Please include when you first started developing this idea, and why you think it is appropriate for Platform (max. 500 words) *
The idea for this proposal has been developed alongside my PhD studies at SHU, where I am a practice-based researcher in the arts and media subject area. My research is concerned with experiences of distractibility that are said to have emerged alongside the recent widespread adoption of digital communications technologies. I’m interested in the way digital systems can be understood as data streams or cloud processes, and how this might impact on the way we attend to them, or how they algorithmically attend to us. My artistic practice often appropriates pre-existing images, software or datasets as ready-mades, and uses computer programming techniques to modify them or highlight their particular characteristics.
Attention is often considered a scarce resource in an age where constant emails, notifications and status updates compete for our cognitive focus. Alongside this scarcity of human attention, recent years have seen an exponential rise in the ‘machine reading’ of images (Hayles), where algorithms are routinely used to analyse the visual characteristics of images. It’s now commonplace for a digital camera on an iPhone to use face recognition algorithms to identify the optimal area to focus on, with some mobile devices going as far as automatically capturing the image when a smiling subject is detected. While many of these recognition algorithms are hard-coded into consumer software and devices, there are some that are more accessible to users.
For this project, I aim to use a range of these computer vision APIs (application programming interfaces) to explore Site Gallery’s database of exhibition and event documentation images that is made available through the gallery website and marketing channels. This will generate a series of images that present this material through the lens of machine vision. I intend to mainly use the Google Vision API, which offers a powerful set of image analysis algorithms that can perform a wide range of tasks. Google Vision can identify faces and provide an estimate of the emotion on the face; can identify landmarks; will isolate and recognise text; as well as providing image analysis data such as the quantity of colour or brightness in the image.
I’m curious about what might be revealed through the process of passing the gallery archive images through this system. Could the sentiment analysis be instrumentalised as ACE evaluation feedback? Is there a preference for particular colour schemes, subject matter, or other identifiable features? What are the implications for the gallery in terms of data stewardship? More broadly, what might machine vision see in an artwork that a human reader might overlook?
I anticipate that the results will invite readings that question the stability of archives while also presenting a perhaps sobering sense of the capability of commonly used image analysis algorithms to identify and reinterpret images as data artefacts.
Describe your idea and how you will approach this as a Platform project.
What resources will you need (max. 500 words) *
Development of the system:
Since coding can be quite a solitary activity and isn’t particularly accessible to an audience, I anticipate having the bones of a working system ready in advance of my arrival onsite. In the weeks prior I would hope to liaise with the gallery web team and begin to make sense of the structure of the image archive, and start to process the images in preparation for analysis. In the very early stages of the onsite phase of the project, the code could be projected to make it available for scrutiny in a similar way to ‘algorave’ events.
Processing of images:
I will aim to produce a system that makes the process of the analysis of the images visible. This is likely to be a screen-based interface that will show the image on the way in to the analysis process, and then combine this with the images produced by the machine vision system.
Display of images:
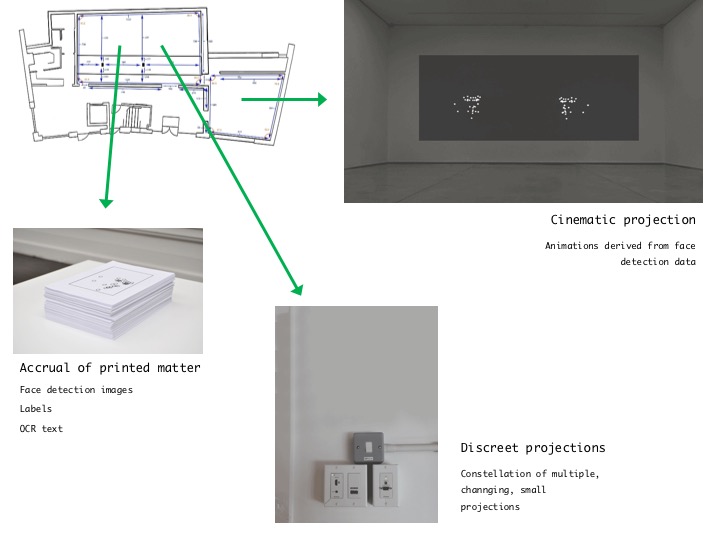
I anticipate that the residency will generate a large quantity of images, perhaps three or more per source image, each with a very specific aesthetic. With the Google Vision API, faces can be identified by ‘landmarks’ such as ‘left_eye’, ‘mouth_left’ and so on, and this information compiled into a very visually reductive image. Colour distributions and tags can also generate images. (See the API demo GIF in my supporting material.) I anticipate the gallery gradually filling with a set of images that have been produced by the algorithm in response to the archive, and are representative of the data contained in the archive while having their own specific aesthetic quality that is very different to the source images.
In previous work, I have presented visual data as an infrastructure that competes for invisibility with physical characteristics of the gallery space, such as cable trunking and air vents, that are supposed to be ignored by the viewer. In Site, the long gallery back wall presents itself as a likely location for a sequential projection of images, and by the end of the residency I would aim to fill as much wall space as possible with these projected images. I would also like to explore the possibility of outputting the data-images produced onto the Site website, temporarily allowing them to replace their sources.
Gallery resources / Production budget:
The main gallery resources I’ll need while onsite will be access to projectors, computers, and installation assistance. Prior to beginning the residency, I’ll need access to the archive of images and communication with the web team in order to get the sources together. There will be some costs involved in the use of the API, but I’m hopeful these can be kept to a minimum.
Presentation